
Approved Once. Trusted Forever. That’s the Problem.
Why tool trust is the weakest link in agentic AI?
Like every handyman, every AI agent needs a good set of tools. It’s how they get the job done.
But how do you know if you can trust the MCP servers you use?
Welcome to another supply chain attack vector into your organization.
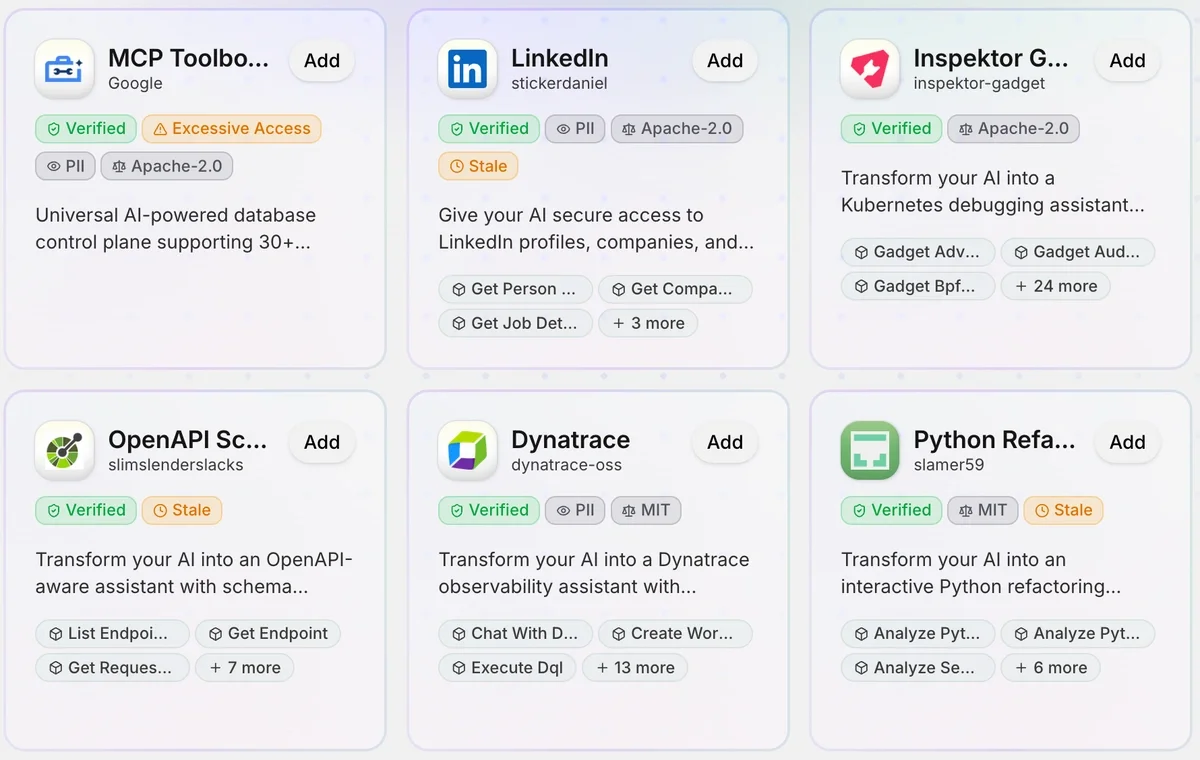
We recently introduced security-related badges to our catalog, so now you know what's safe or not!
The Risk Behind MCP Servers
In MCP-based systems, those tools are code-level components that developers connect to execute logic - scripts, wrappers, connectors, and callable functions that MCP servers make available to agents. These tools run on developer machines, in containers, or on browser-based agents, often with credentials that grant them broad access to production systems and sensitive data.
The thing is, once a tool is approved and used by a developer, it generally stays trusted. No one checks if the code changes. No one tracks where it runs or who owns it. The agent just keeps going - calling logic that may no longer behave the way it did on day one. It’s the same pattern we see with AI-generated code: logic reaches production without review. If only 24% of organizations conduct reviews of their own AI-generated production code, how many are reviewing the developer tools their AI agents rely on?
Needless to say, these MCP servers are just downloaded straight from the internet, to say, github, or other places. There's no way knowing if they are malicious or vulnerable. Just like Node packages, and recently the Shai Hulud insane worm, show that the risk is there. Developers are being targeted.
In November 2025 the first malicious MCP was found in the wild, it was the Postmark MCP (wrapping the online services of mass email sending). Everything was fine about it, except one line of code which configured the BCC field to leak all emails sent. Good luck spotting it. If there's one, there will be more.
Talking with security teams, we ask them - "how do you approve MCP servers?", and the answers aren't great - looking at github stars and whether the project is maintained. Even if a project started well, we all know it can go rogue one day, there are multiple stories where one maintainer became corrupt.
The end result is an execution layer that’s essentially built on invisible assumptions. In this blog, we’ll look at how developer tools shape agent behavior, how trust becomes a standing permission, and how that permission can turn execution into exposure.
Tools Are How Agents Take Action
Tools are the mechanism by which agents act. Each one handles a specific job - retrieving structured data, manipulating the response, sending a task to another system. The agent gives the instruction. The tool carries it out.
These tools are code modules built or assembled by developers. Some run locally, others are already official (hosted by the software vendor just like HTTP servers). Many come from open-source registries, internal code sharing, or locally configured MCP servers that are used for testing or quick integration. Each tool is integrated by the developer into the agent’s execution path and runs logic on its behalf.
As mentioned, most tools are added to workflows with minimal review. Once they work, they stay. They become part of a system that accesses live data and production environments, often without authentication, inspection, or version control.
This doesn’t happen out of negligence, developer oversight, or malice. It happens because speed is the rallying cry of AI development. Teams are under pressure to ship fast, integrate quickly, and show value early. Tools that get something working are kept in place because they save time. Once an agent runs without errors, the work moves on.
And it's getting even worse because we can’t ignore the issue of “consent fatigue.” Over time, developers effectively become the human-in-the-loop for code generation alongside their coding agents. Because they are always the source of the prompt and generally know what to expect, they tend to allow commands to auto-run without scrutiny. In some cases, it isn’t even an MCP tool that wipes an entire hard drive—the agent itself decides to issue a destructive OS filesystem command like 'rm'. Without proper guardrails, this is still deeply concerning. The core problem is that once an agent chooses to invoke a connected MCP in auto-run mode, there is no real mechanism to stop it, and mistakes are inevitable and we can't blame developers for auto-approving all commands, it only makes sense.
A Clear and Present Danger
Once tools become part of agentic workflows, they inherit trust - and that trust is rarely revisited. These tools function as a hidden software supply chain embedded inside the agent’s logic. While that structure improves productivity, it also introduces risks that are easy to miss, including:
-
Unmaintained, Abandoned or Forked Tools
Tools built for short-term use, often stay connected long after their last update. Many run on stale dependencies or unpatched modules yet still hold valid credentials and system access. Without an automated process to retire them or monitor for changes in their dependencies/libraries, functionality becomes the only metric for trust. Because of MCP hype, by now we already see abandoned servers with unpatched vulnerabilities. -
Tool Impersonation and Replacement
Attackers can introduce malicious clones of legitimate tools into open repositories or internal registries. These fakes mimic naming, interface structure, and metadata to pass as trusted components. Once connected, they inherit the same permissions and agent trust as the original. MCP-based agents have no built-in way to tell the difference. -
Behavioral Drift After Approval
Tools evolve. Developers push updates and modify logic - and often inadvertently change how tools execute behind the scenes. In most environments, those changes go live without triggering a review. The agent calls the same function name and assumes the same behavior - regardless of what the tool now does behind the scenes. -
Malicious Tool Outputs as Control Signals
Tools don’t just complete tasks. They shape what happens next. When a tool returns a result, normally the AI agent, or the model specifically behind it, has to further process it. A manipulated output - like crafted metadata or injected text - can steer the agent toward unexpected decisions eventually comprising the agent with a prompt injection.
What Security Isn’t Catching - And What Needs to Change
AI agent tools operate in a layer that traditional security doesn’t even observe. Application security focuses on the app, not the tool that called it. Dependency scanning maps package trees but not runtime logic. Model governance tracks prompts and responses but not what happens between them.
Meanwhile, agents keep calling code that no one reviews.
To rectify this, security leaders should shift focus to the layer where AI-driven execution happens. That means maintaining a full inventory of connected tools, enforcing ownership over MCP servers, monitoring behavior in context, and setting clear thresholds for when tools must be revalidated or retired.
Tool trust is an infrastructure-level decision that shapes how agents behave inside live systems. It deserves the same scrutiny as any other attack surface. Approved once shouldn’t mean trusted forever.
Conclusions
We introduced two issues when using tools like MCP servers in your agentic workflows:
-
The lack of trust of using unsanctioned MCP servers downloaded from the internet, which can also change over time.
-
The consent fatigue situation and where models can hallucinate and create a destructive command which has no 'undo' button.
To mitigate the former, we created a securely-vetted catalog where we can each and every MCP server to check for vulnerabilities, looking for malicious activity, checking related URLs in the code for their reputation and come up with a final score.
Each MCP server in our catalog contains security status:
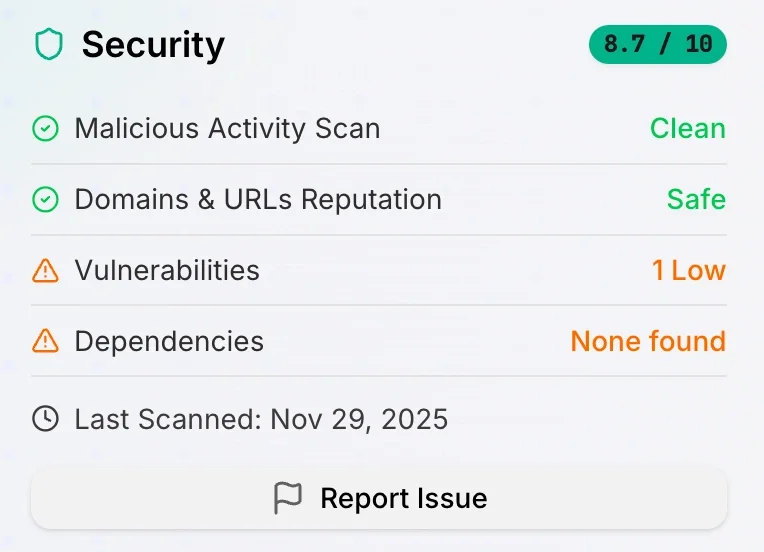
And the most important thing is to know it's not malicious.
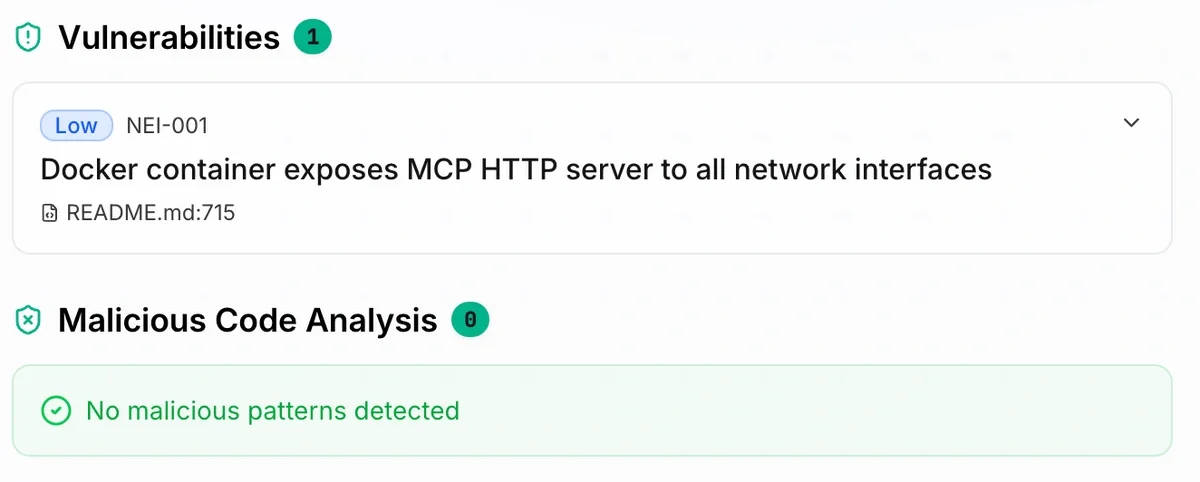
As for the latter issue with destructive commands, hopefully we will start seeing the models become more responsible and probably more coding agents' plugins trying to assess whether a command is safe or not.
Browse our catalog and launch safe MCP tools.